Toto je 3. diel série článkov o verzionovacom systéme Git. V minulom diely (Lokálna Práca so Súbormi – 2. diel) sme si čo to povedali o základnej práci so súbormi. Ako už názov napovedá, tejto oblasti sa budeme venovať aj teraz, pozrieme sa na ďalšie operácie, ktoré umožňuje Git so súbormi robiť a tiež si povieme niečo viac o tom, ako si vlastne Git interne uchováva stav repozitáru. Git je mocný nástroj na správu verzií, ktorý umožňuje vývojárom sledovať a riadiť zmeny v ich projektoch. Kým väčšina používateľov pracuje so základnými príkazmi Git na každodennej báze, v tomto článku sa ponoríme hlbšie do toho, ako Git spravuje súbory a adresáre v pozadí. Porozumieme týmto mechanizmom a naučíme sa lepšie využívať Git v našich projektoch.
Rýchle preopakovanie alebo kde sme to skončili
V poslednom diely sme si ukázali, ako sa dá prezerať história Gitu. To je vlastne séria commitov, ktoré na seba nadväzujú. História obsahuje okrem samotných zmien aj informácie o tom, kde a kedy zmenu spravil. Tiež sme si povedali, ako povedať Gitu, aby niektoré súbory alebo zmeny v nich ignoroval. Zatiaľ sme ale so súbormi robili v podstate len dve jednoduché operácie: pridanie a zmenu. A to je málo, takže sa poďme pozrieť, čo sa s nimi ešte dá robiť.
Základná štruktúra Git repozitára
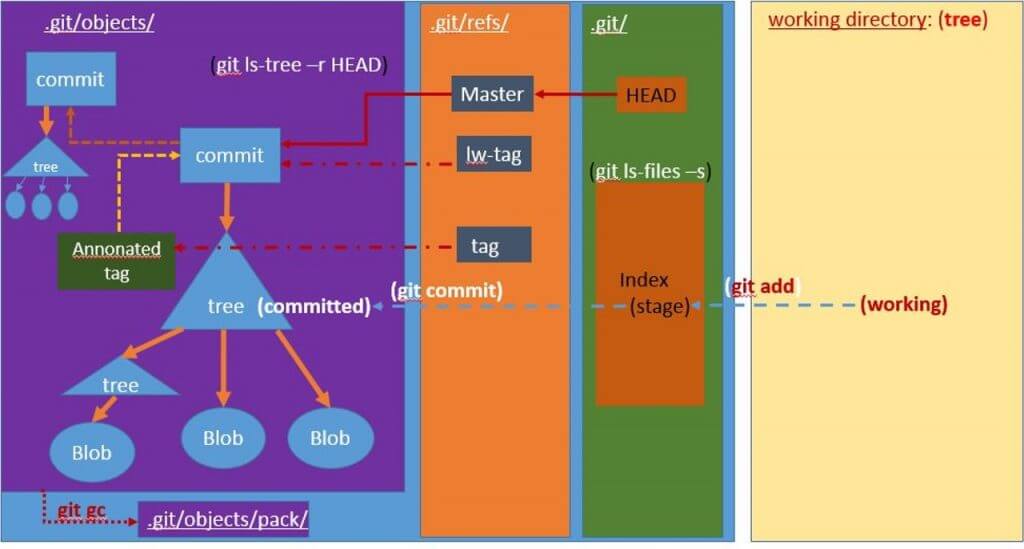
Git repozitár pozostáva z 3 hlavných častí: pracovný adresár, staging area (index) a repozitár. Každá z týchto častí zohráva kľúčovú úlohu v tom, ako Git spravuje a sleduje zmeny v projekte.
- Pracovný adresár (Working Directory):
- Obsahuje všetky súbory a adresáre projektu.
- Tu sa vykonávajú všetky zmeny a úpravy súborov.
- Staging Area (Index):
- Medzistupeň medzi pracovným adresárom a repozitárom.
- Súbory pridané do staging area sú pripravené na commit.
- Repozitár (Repository):
- Obsahuje všetky commity a históriu projektu.
- Uložené v
.gitadresári.
.git adresár
Adresár .git je srdcom každého Git repozitára. Obsahuje všetky údaje potrebné na správu a sledovanie verzií projektu. Pozrime sa na kľúčové súbory a adresáre v tomto adresári:
- HEAD:
- Ukazuje na aktuálny commit alebo vetvu.
- Obsahuje referenciu na posledný commit v aktuálnej vetve.
- config:
- Konfiguračný súbor repozitára.
- Obsahuje nastavenia, ako sú užívateľské meno, e-mail a ďalšie možnosti.
- refs:
- Obsahuje odkazy na všetky vetvy a tagy.
refs/heads/pre lokálne vetvy.refs/tags/pre tagy.
- objects:
- Obsahuje všetky objekty (bloby, stromy a commity).
- Uložené podľa ich SHA-1 hashu.
- index:
- Predstavuje staging area.
- Obsahuje zoznam súborov pripravených na commit.
Objekty v Git
Git spravuje tri typy objektov: bloby, stromy a commity. Tieto objekty sú základom toho, ako Git sleduje a ukladá zmeny v projekte.
- Blob (Binary Large Object):
- Reprezentuje obsah súboru.
- Každý súbor je uložený ako blob s jedinečným SHA-1 hashom.
- Tree:
- Reprezentuje adresár.
- Obsahuje odkazy na bloby a ďalšie stromy.
- Commit:
- Reprezentuje zmeny v projekte.
- Obsahuje odkaz na strom, predchádzajúci commit, autora, čas a commit message.
Príklady:
git cat-file -p <tree_sha> # Zobrazenie obsahu stromu
git cat-file -p <commit_sha> # Zobrazenie obsahu commit-u
Mazanie súborov – príkaz rm
Ak verzionuješ súbory, nie je nič úplne jednoduché. Ani ich mazanie. Aj preto na to v Gite existuje špeciálny príkaz git rm. Ten je nutné použiť vtedy, ak ideš mazať súbor, ktorý bol už pridaný do staged changes (nemusí byť ale commitnutý). Takýto súbor je už pod dohľadom Gitu, a preto ho nestačí len zmazať z disku, ale je dobré povedať Gitu, že len tak nezmizol, ale že si ho chcel naozaj zmazať (ak súbor nebol ešte nikdy pridaný pomocou git add, tak ho môžeš jednoducho zmazať pomocou príkazu operačného systému).
Ako sme si povedali hneď v prvom diely, zmeny uložené v Gite sú vo veľkej miere perzistentné, to znamená, že história (pokiaľ to vyslovene neprikážeš) sa nemení. Platí to aj pre mazanie, kedy sa maže len posledná verziu súboru a jeho zmiznutie bude uložené s najbližším commitom. Znamená to, že celá história súboru (jeho pridanie aj zmeny v commitoch) v repozitári ostávajú a ty sa nemusíš báť ho zmazať, lebo máš svoj stroj času, ktorým vieš jeho obsah získať kedykoľvek späť.

Poďme si ukázať jednoduchý príklad. Najprv do nášho minirepozitára, ktorý sme používali aj v predchádzajúcich dieloch pridaj prázdny súbor register.html. Následne ho pridáme do staged changes a commitneme.
> git add register.html
> git status short
A register.html
> git commit -m „Pridany subor pre test zmazania“
[master bba57e4] Pridany subor pre test zmazania
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 register.html
Súbor register.html je teraz súčasťou histórie repozitára. Je na čase ho zmazať:
> git rm register.html
rm ‚register.html‘
> git status –short
D register.html
Zmazanie je pripravené v staged changes, ostáva už len commit:
> git commit -m „Odstranenie testovacieho suboru“
[master 74622d0] Odstranenie testovacieho suboru
1 file changed, 0 insertions(+), 0 deletions(-)
delete mode 100644 register.html
Ak si dáš zobraziť obsah priečinku, tak zistíš, že sa už v ňom register.html nenachádza.
Zmazanie projektov alebo ten pocit keď musíš mazať svoju prácu
Ak si niekedy pracoval na projektoch, ktoré nepoužívali verzionovací systém, tak si možno spomínaš na ten nepríjemný pocit, keď si mal zmazať časť alebo celý súbor zdrojového kódu. Prvé, čo ťa v takom momente stretne, je pochybnosť či je mazanie dobrý krok. Či tento kus súboru alebo celý súbor ešte náhodou nebudeš potrebovať. Výsledkom môže byť, že ho radšej nezmažeš. Súbor necháš pohodený niekde v projekte, a ak robíš s kompilovaným jazykom, tak jeho obsah ešte zakomentuješ, aby ste ho nemuseli pre kompilátor udržiavať.
Ruku hore, kto sa dostal na projekt, kde sa sem-tam povaľovali kusy kódu s komentárom „Nemazať – možno sa ešte zíde“. Ja viem, že zahadzovať svoju prácu bolí, ale som toho názoru, že živého kódu je v projekte väčšinou toľko, že mŕtve kusy kódu a bludne osirotené súbory už naozaj nikto k šťastiu nepotrebuje.
Git (ale aj iné dobré verzionovacie systémy) je úžasný vývojársky nástroj. Rieši za teba mnoho problémov a dokáže ťa aj zbaviť bremena voľby, či nejaký kód môžeš alebo nemôžeš zmazať. Ale obed zadarmo to nie je. Je potrebný systém a disciplína v používaní Gitu, aby si sa na neho vedel 100 % spoľahnúť vo veciach, v ktorých ti môže pomôcť. Čo teda musíš robiť preto, aby si mohol bez váhania mazať?
- Je potrebné commitovať. Dokážeš obnoviť len kód, ktorý už bol commitnutý. Preto žiadne niekoľkodňové práce bez jediného commitu. Minimalistické pravidlo je 1 commit za 1 deň. Ale čím častejšie tým lepšie. Git by mal do určitej miery sledovať zmeny, ktoré v svojich súboroch robíš, aby ti vedel potom spätne pomôcť. Bez záznamu histórie nemôžeš cestovať v čase. A čo ak máš rozpracované niečo väčšie, čo jednoducho za jeden deň nedokončíš? Vytvor si branch a zmeny commituj do neho (ja viem, branch sme ešte neprebrali – dôjdeme aj k tomu)
- Commituj zodpovedne. Pamätám sa na 1 projekt, kde bol log verzionovacieho systému plný prázdnych správ alebo správ typu F*ck. Je síce pekné, že autor zaznamenal svoje emocionálne rozpoloženie, ale pri študovaní histórie to bolo len veľmi málo osožné. Vlastne celá taká história sa mohla zahodiť do koša. Bolo to ako listovanie v atlase dejepisu, kde sú len obrázky bez textu a ty môžeš hádať čo, kedy a kde sa na obrázku odohráva. Ak chceš pracovať s históriou, musíš písať zmysluplné hlásenia správ, aby si sa v tom potom vedel zorientovať. Napríklad „Mažem súbory“ je zlé, ale „Refactoring servisnej vrstvy vzhľadom na nové rozhranie … „ je lepšie. A to je len názov, za ktorým by mal nasledovať trochu detailnejší opis, aký cieľ sa mal zmenou dosiahnuť. Tiež by si nikdy nemal commitovať nesúvisiace zmeny naraz. Na to existuje staged changes, aby si si do neho uložil to, čo je pripravené na commit a odtiaľ to commitol.
Bez správneho commitovania to nepôjde. Rob všetko preto, aby si si z commitovania urobil reflex. Ideálny stav je, ak po dlhodobejšej intenzívnej práci na súboroch (3-4 hodiny) začneš mať nutkanie typu „Urobil som už fakt veľa zmien. Bolo by dobré ich commitnúť“. Takýto pracovný návyk spolu so zručnosťou pracovať s Git históriou ťa zbaví akýchkoľvek pochybností, či môžeš nejaký kus kódu zmazať. Samozrejme, že môžeš. Veď je to v Gite.
Presúvanie súborov – príkaz mv
Po mazaní tu máme ďalšiu pomerne bežnú operáciu so súbormi – presúvanie. Čo je na presúvaní verzionovaných súborov také komplikované? Hlavne to, že ak súbor presunieš z jedného priečinka do druhého, tak pre teba je to stále ten istý súbor, u ktorého chceš vedieť jeho históriu. Verzionovací systém sa ale na to môže pozerať tak, že pôvodný súbor zmizol (bol zmazaný) a na inom mieste vznikol nový – bez histórie.
Do akej veľkej miery s tým verzionovací softvér problém bude mať záleží od toho, ako si interne ukladá informácie o stave sledovaných súborov. Git patrí k tým systémom, ktoré náhly presun až tak nevadí a dokážu sa s ním vysporiadať. Problém môže nastať, ak súbor presunieš a bez toho, aby si zaznamenal zmenu do staged changes, súbor na novom mieste hneď zmeníš. Z toho sa už nemusí spamätať ani Git. Aj preto je dobré si jednoducho zvyknúť na to, že ak presúvaš súbor, tak to rob pomocou príkazu git mv.
V našom testovacom git repozitári zatiaľ máme len jeden súbor, a preto na testovanie presunu si v ňom vytvor najprv podpriečinok (napr. subdir). Následne presunieme súbor index.html do podpriečinku:
> git mv index.html subdir
Skontrolujeme stav:
> git status –short
R index.html -> subdir/index.html
Git presun pekne rozpoznal. Zatiaľ je to samozrejme len pripravené v staged changes a do histórie repozitára to môže vstúpiť len ako súčasť commitu. Príkaz mv (ako už býva dobrým zvykom) slúži aj na premenovanie súboru, nie len na presun.
Pri presúvaní súborov a premenovaní vie Git ukázať trochu mágie, ktorú ovláda. Predstav si, že by som zabudol súbor do podadresára subdir presunúť pomocou príkazu Gitu. Presunul by som ho jednoducho príkazom operačného systému (alebo by to za mňa urobilo moje IDE). Kontrola stavu working copy by ukázala niečo takéto:
> git status –short
D index.html
?? subdir/
To je celkom logické. Git vidí, že pôvodný súbor zmizol (predpokladá, že bol zmazaný, a preto ho aj tak označil) a na druhej strane sa mu objavil priečinok subdir s nesledovaným súborom. To je ten moment, kedy si vývojár plesne po čele, usrkne trochu kávy a zadá príkazy:
> git rm index.html
rm ‚index.html‘
>git add subdir\index.html
Urobil som teda poriadok v informáciach čo so súbormi a idem znova skontrolovať stav working copy:
> git status –short
R index.html -> subdir/index.html
A je to tu. Git to všetko pochopil a magicky vydedukoval, že súbor bol vlastne presunutý. V skutočnosti to nie je až taká mágia, ako by sa mohlo zdať. Pre Git je totiž kľúčový obsah. Nie nadarmo má nálepku content-adressable filesystem. Tá nálepka vypovedá o tom, ako Git vlastne pristupuje k súborom v repozitári a ako si o nich a ich zmenách uchováva informácie. Každopádne je to nálepka, ktorá zasluhuje vysvetlenie, a preto je na čase, aby sme pozreli trochu pod povrch toho všetkého. Z hlboka sa nadýchni, čaká nás ponor do hlbín súborového systému Gitu.
Hash je kľúčom ku všetkému
Doteraz sme o Gite hovorili ako o systéme na verzionovanie súborov. Ale ak odlupneme všetky vrstvy, ktoré slúžia na spravovanie súborov, priečinkov a commitov, dostanem niečo celkom iné. Dostaneme key-value databázu.
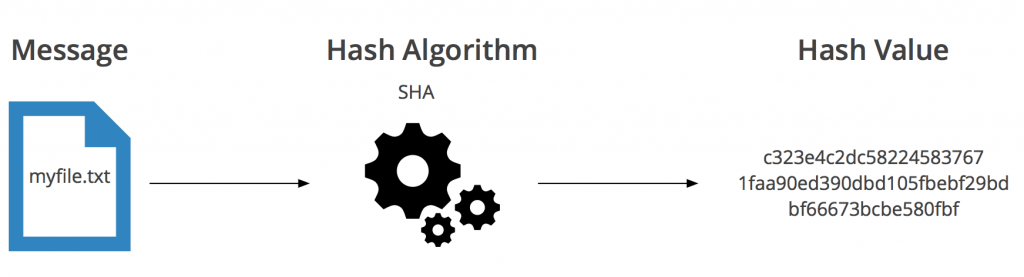
Git v sebe obsahuje mechanizmus, ktorý umožní ľubovoľný obsah, či už textovú reťaz, alebo binárne dáta, zapísať ako hodnotu do databázy a automaticky k tejto hodnote vypočíta jej SHA1 hash. Vo svojej najjednoduchšej podstate je hash-based storage system. Na tomto princípe je postavené celé ukladanie stavu repozitára, preto pri ňom začíname, a preto je dôležité ho pochopiť. Poďme si ukázať, ako to vlastne funguje. Do nášho Git repozitára si uložíme textový reťazec:
> echo ‚Toto je ukladany text‘ | git hash-object -w –stdin
281a90ae11585a50d9add1e49bb5c8c84df98f44
git hash-object je príkaz, ktorý vyráta pre nejaký obsah jeho SHA1 hash. Prepínačom –stdin sme mu povedali, aby bral obsah zo štandardného vstupu (v našom prípade sme presmerovali výstup príkazu echo). A prepínačom -w sa mu povedalo, aby ten obsah zapísal ako blob do databázy repozitára (bez neho by len vyrátal samotný hash a nič neuložil). Čo to je blob, k tomu sa o chvíľu dostaneme, teraz si stačí len uvedomiť, že sme práve do repozitára uložili reťazec ‚Toto je ukladany text‘ a dostali sme naspäť jeho hash, ktorý zároveň slúži ako kľúč, ak sa chcem k obsahu dostať. Poďme teda vytiahnuť hodnotu späť:
> git cat-file -p 281a90ae11585a50d9add1e49bb5c8c84df98f44
‚Toto je ukladany text‘
git cat-file je presne príkaz, ktorý teraz potrebujeme, pretože vytiahne obsah na základe hashu. Prepínačom -p sme mu len povedali, aby ho nejako normálne zobrazil, podľa toho o aký obsah ide. Vieme teda uložiť ľubovoľný obsah a načítať ho. To je fajn, ale k verzionovaciemu systému to má ešte ďaleko. Pred chvíľou som spomenul, že obsah bol uložený ako blob. Je na čase si povedať, čo to je.
Obsah, to je blob
Ak sa na chvíľu zamyslíš, čo to vlastne súbor je, tak ťa asi napadne, že je to zhluk informácií, ktorý zahŕňa jeho obsah, názov, autora, prístupové práva a možno aj súborovú cestu, na ktorej je uložený. Git sa na to pozerá trochu inak a samotný obsah súboru oddelil od všetkého ostatného. Ukladá ho do takzvaných blobov, čo je prvý typ dátového objektu, o ktorom si niečo povieme.
Prvý blob sme vytvorili už v predchádzajúcom príklade pomocou hash-object s prepínačom -w. Teraz si to ale skúsime na ozajstnom súbore. V koreňovom priečinku repozitára vytvor súbor „test“, ktorý v sebe bude obsahovať vetu: „Text testovacieho súboru“ (bez úvodzoviek). Následne ho necháme uložiť do repozitára Gitu:
> git hash-object -w test
10495e0ff03540101c92d01571eb21e37e53a29e
Tentokrát sme príkazu neposlali vstup z klávesnice, ale súbor a on uložil jeho obsah a vrátil nám kľúč, pod ktorý ho uložil. Ak chceš, tak môžeš použiť príkaz cat-file na vypísanie jeho obsahu. Zaujímavé na tom hashi je, že ak si skúsiš obsah toho súboru zahashovať cez nejaký štandardný nástroj (online, alebo cez command line tool), nebude výsledok (aj v prípade použitia toho istého algoritmu) rovnaký. Je to preto, lebo Git na začiatok obsahu vloží ešte niekoľko svojich technických informácií (viac informácii nájdeš tu).
Ak patríš k tým, ktorí sa radi vŕtajú vo veciach, kým ich nerozoberú a úplne nepochopia, môže ťa zaujímať, kde vlastne je fyzicky ten blob uložený. Je na čase pozrieť si priečinok .git (pozor je skrytý) a v ňom podpriečinok objects. To, čo uvidíš, je sada podpriečinkov s dvojmiestnym názvom. Tie názvy predstavujú prvé dve písmená z hashu objektu (Git ich takto ukladá kvôli zrýchlenému vyhľadávaniu). Ak niektorý otvoríš, uvidíš v ňom súbory, ktoré predstavujú bloby. Názov súboru predstavuje hash bez prvých dvoch znakov.
V priečinku objects ale nie sú uložené len bloby, ale aj ďalší typ objektu – tree.
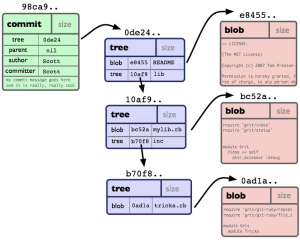
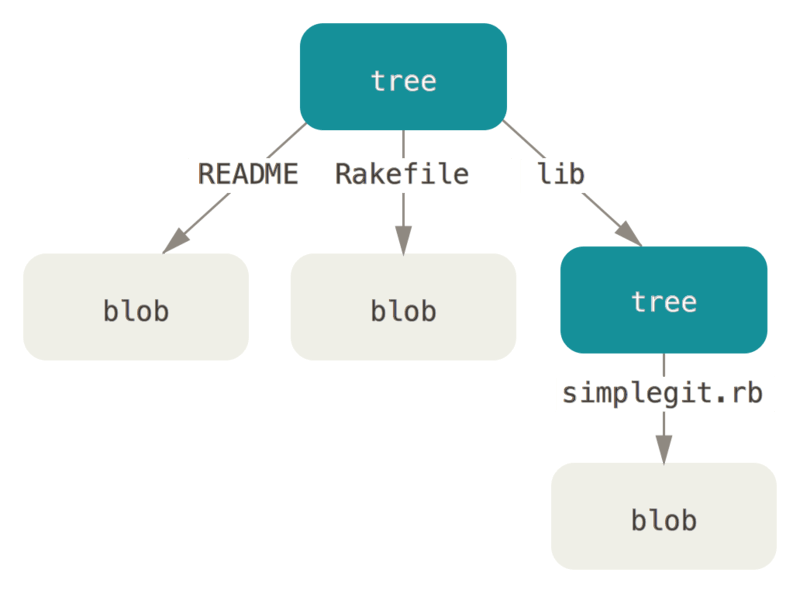
Priečinok, to je tree
Tree je ďalší typ dátového objektu Gitu, ktorý v podstate reprezentuje priečinok. Sám o sebe predstavuje dátovú štruktúru, ktorá je uložená v repozitári a má priradený hash. Tree v sebe obsahuje odkazy na iné tree alebo bloby (teda ich hashe) a zároveň informácie o danom objekte. Vzťah medzi tree a blobom sa dá zakresliť takto:
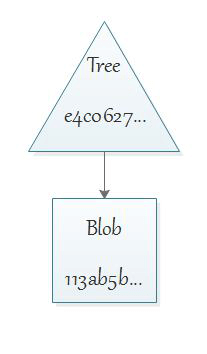
Ak si dokončil vo svojom testovacom repozitári presun súboru pomocuu príkazu mv, tak si vieš jeden taký tree objekt pozrieť. Najprv potrebuješ získať hash commitu, ktorý urobil presun:
> git log
commit ce3944e86fa3cdf3458620634f7ae74328ccea5e
Author: Miroslav Reiter <miroslav.reiter@it-academy.sk>
Date: Fri Apr 15 13:20:18 2021 +0200
Presun suboru
…
Následne si zobrazíš obsah commitu:
> git cat-file -p ce3944e86fa3cdf3458620634f7ae74328ccea5e
tree a382cc83526601fb67c6927509aa7424d2f2f376
parent 74622d07d664f9d45fb29bd3355bbf2e0d63b6d9
author Miroslav Reiter <miroslav.reiter@it-academy.sk> 1460719218 +0200
committer Miroslav Reiter <miroslav.reiter@it-academy.sk> 1460719218 +0200
Opäť je tu príkaz cat-file s prepínačom -p, ale tentokrát sme mu dali hash commitu, a tak je výsledok iný ako keď sme mu dali spracovať blob. Vo výpise vidíme tree objekt aj s jeho hashom, takže opäť cat-file na tree objekt:
> git cat-file -p a382cc83526601fb67c6927509aa7424d2f2f376
040000 tree 1648d04e39b309aaa45ee04729096d084b670d88 subdir
To, na čo sa pozeráme, je tree objekt popisujúci koreňový priečinok. Obsahuje v sebe 1 podpriečinok – subdir, ktorého hash môžeš vidieť. Ak použiješ cat-file s týmto hashom podpriečinku, tak získať výpis jeho obsahu. Takto sa dá pokračovať ďalej a postupne prechádzať celá štruktúra repozitára.
Uchovávanie obsahu a informácií o štruktúre už máme. Takto ale vieme uchovať len jeden stav v čase a my potrebujeme zaznamenávať históriu zmien. A preto tu máme 3. typ dátového objektu – commit.
Commit, to je … vlastne commit
S commitmi sme sa stretávali už od 1. dielu série. Už teraz vieš, že majú priradený svoj hash a že nadväzujú jeden na druhý a tak tvoria históriu. Sú ďalším typom dátového objektu, ktorý sa ukladá do repozitára ako objekt uložený pod hash kľúčom. Každý commit obsahuje odkaz na práve jeden tree objekt (ten, ktorý reprezentuje koreňový priečinok), hash odkaz na svojho predka a ostatné informácie o commite. Ak dokreslíme do nášho obrázku commit, môže to vyzerať takto:
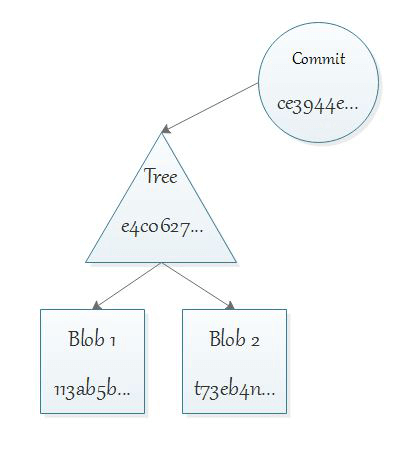
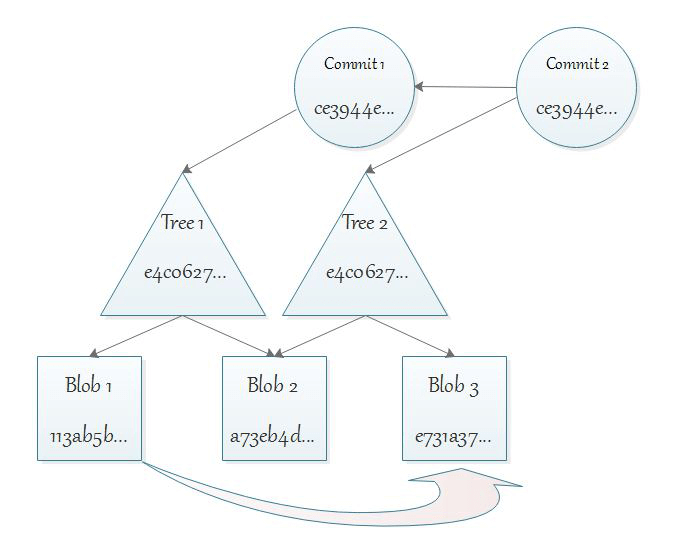
Commity slúžia na prezentovanie zmeny. Zmena je vlastne nový stav working copy (resp. stav, ktorý bol pridaný do staged changes), plus niekoľko informácií naviac (kto a kedy urobil zmeny atď.). Každý commit sa teda musí odkazovať na stav working copy, a ak vytvoríme nový commit, tak ten musí obsahovať odkaz na novú štruktúru:
Content-adressable filesystem
Ako som napísal vyššie, Git je content-adressable filesystem a ty už asi teraz tušíš prečo. Obsah súborov je reprezentovaný hashom. Všetko ostatné je potom vystavané na odkazoch na tieto obsahy súborov. V Gite nedokážeš pridať do repozitára prázdny priečinok. Je to v podstate dizajnové rozhodnutie, pretože všetko začína obsahom súborov a ostatné je na tom postavené. Blob, tree, commit – to všetko sú objekty uložené v hash-based databáze, ktorá predstavuje základ Gitu.

Toto ukladanie obsahu na základe hashu je predpoklad, aby repozitár príliš nerástol. Aj keď sme súbor test uložili ako blob, Git ho nevidí ako verzionovaný súbor, lebo na neho neodkazuje žiaden tree objekt. Môžeš ho teda pridať pomocou príkazom add a commit. Ak to spravíš, tak zistíš, že žiadny nový blob nebol pridaný (len nový tree a commit objekt). Je to preto, lebo Git vyrátal hash tohto súboru a zistil, že taký obsah už existuje. A teda nevytváral nový blob, len použil referenciu na existujúci.
To je dôležitejší princíp, ako by sa na prvý pohľad mohlo zdať. To totiž znamená, že Git pri zaznamenávaní nového commit – čo je vlastne snapshot aktuálneho stavu working copy – reálne vytvorí len nové objekty pre tie, ktoré ešte vo svojej databáze hashov nemá. Git neuchováva inkrementálne rozdiely medzi commitmi. Uchováva kompletné snapshoty súborovej štuktúry, ale zároveň šetrí vytváranie nových objektov, kde sa dá.
Záver a sumarizácia
Git je komplexný nástroj, ktorý ponúka veľkú flexibilitu a kontrolu nad správou verzií. Pochopenie vnútorných mechanizmov Git, ako sú objekty, vám umožní lepšie využiť jeho schopnosti a efektívnejšie spravovať vaše projekty. Pri príkaze mv sme si ukázali trochu mágie Gitu. Súbor sme presunuli bez toho, aby sme to Gitu povedali a on to aj tak uhádol, že sme to spravili. Kľúčom k tomu je, že aj po presune mal ten súbor (ako BLOB) rovnaký hash ako pred presunom. To je dôvod, prečo Git uhádol, že to bude ten istý. Ak chceš Gitu naozaj rozumieť, tak je nevyhnuté aspoň z časti pochopiť ako funguje vo vnútri. Len tak sa dá tiež pochopiť jeho správanie navonok a hlavne bude práca s ním omnoho predvídateľnejšia. Na projekte, kde máš stovky alebo tisíce súborov, zopár desiatok branchov a niekoľko commitov denne, je dobrá znalosť nástroja, ktorý používaš nevyhnutná.
Dnes to teda bola viac teoretická cesta do hlbín súborového systému. Nabudúce si povieme niečo viac práve o branchovaní a mergovaní.
Odporúčania na prácu s GITom
Pri práci s Gitom dbajte na pravidelné commity, správne používanie vetiev a tagov a využívanie staging area na prípravu zmien. Pochopenie vnútorných štruktúr Git vám umožní lepšie riešiť problémy a optimalizovať váš pracovný proces.
Objavte online kurzy na Git a GitHub
Prehľad publikovaných článkov
- Seriál Online kurz Git – Začíname s Gitom – 1. diel
- Seriál Online kurz Git – Lokálna Práca so Súbormi – 2. diel
- Seriál Online kurz Git – V Hlbinách Súborového Systému – 3. diel
- Seriál Online kurz Git – Paralelné svety a Git branch – 4. diel
- Seriál Online kurz Git – Mergovanie s Konfliktom, Tagy a Skrytie Zmien – 5. diel
- Seriál Online kurz Git – Vzdialené repozitáre, GitHub, Bitbucket – 6. diel
- Seriál Online kurz Git – Clean, Reset, Rebase, Revert nástroje do každého počasia – 7. diel
- Seriál Online kurz Git – Najčastejšie problémy, faily a fuckupy – 8. diel


